Linux简单操作速查
用户操作
修改密码(passwd)
1 | sudo passwd <username> |

创建新用户(adduser)
1 | sudo adduser <username> |
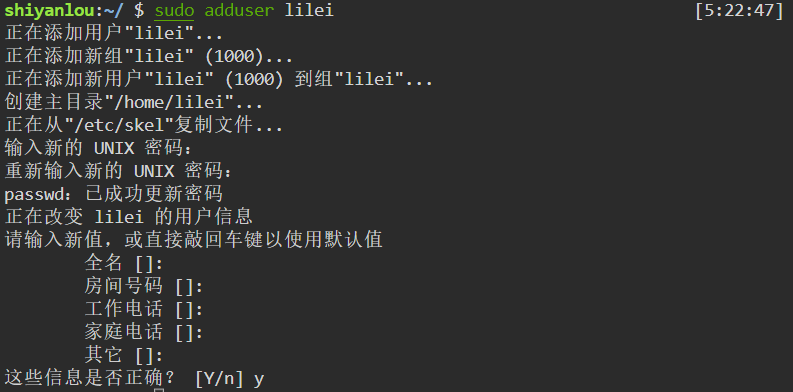
删除用户(deluser)
1 | sudo deluser <username> --remove-home |

查看当前用户(whoami)
1 | whoami |

切换到用户(su)
1 | su -l <username> |

| 参数 | 描述 |
|---|---|
-c |
将 COMMAND 传递至启动的 shell |
-h |
显示帮助信息并退出 |
-l |
将 shell 设为登录 shell |
-p |
不重置环境变量并保持同一 shell |
-s |
使用 SHELL 而非 passwd 中的默认值 |
查看所属用户组(groups)
1 | groups <username> |

其中冒号之前表示用户,后面表示该用户所属的用户组
授予sudo权限
1 | sudo usermod -G sudo <username> |
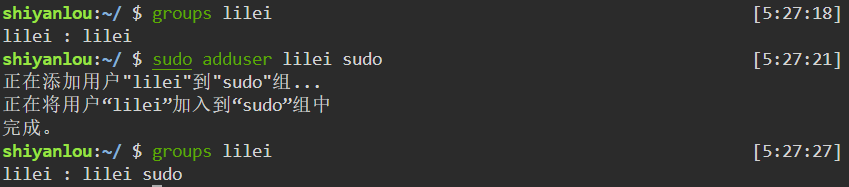
移除sudo权限
1 | sudo deluser <username> sudo |

目录操作
查看当前路径(pwd)
1 | pwd |
| 参数 | 描述 |
|---|---|
-P |
显示实际物理路径,而非使用连接(link)路径 |
-L |
当目录为连接路径时,显示连接路径 |

切换目录(cd)
1 | cd <dir> |
| 命令 | 作用 |
|---|---|
cd ~ |
进入当前用户主目录 |
cd / |
进入系统根目录 |
cd .. |
从当前目录进入父目录 |
cd - |
从当前目录进入上次所在目录 |

查看目录内容(ls)
-
只显示文件名:
1
ls
-
显示详细信息:
1
2
3ll
# 等同于
ls -l参数 描述 -a–all 列出目录下的所有文件,包括以 . 开头的隐含文件 -l除了文件名之外,还将文件的权限、所有者、文件大小等信息详细列出来 -h–human-readable 以容易理解的格式列出文件大小(例如 1K 234M 2G) -t以文件修改时间排序 隐藏文件前带
. -
查看目录完整属性:
1
ls -dl [<dirpath>]
-
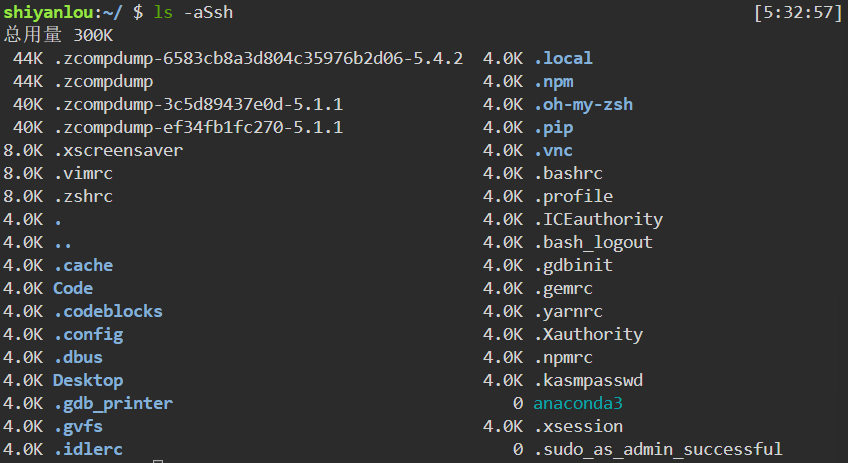
显示所有文件大小
1
ls -aSsh



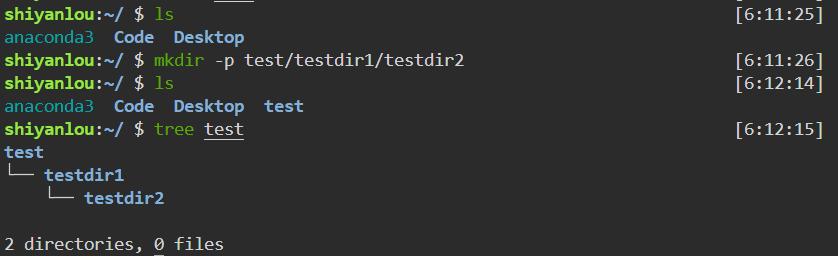
创建目录(mkdir)
1 | mkdir [option] <dir> |
| 参数 | 描述 |
|---|---|
-m |
设定权限<模式> |
-p |
多级创建,可以是一个路径名称。若路径中某些目录尚不存在,系统将自动建立好 |
-v |
每次创建新目录都显示信息 |
删除目录(rm -r)
1 | rm -r [option] <dir> |
| 参数 | 描述 |
|---|---|
-f |
忽略不存在的文件,从不给出提示 |
-i |
进行交互式删除 |
-r |
指示 rm 将参数中列出的全部目录和子目录均递归地删除(删除目录时必须) |
-v |
详细显示进行的步骤 |
复制目录(cp -r)
也就是递归复制文件
1 | cp [option] <dir> <目标位置> |
| 参数 | 描述 |
|---|---|
-t |
指定目标目录 |
-i |
覆盖前询问(使前面的 -n 选项失效) |
-n |
不要覆盖已存在的文件(使前面的 -i 选项失效) |
-s |
对源文件建立符号链接,而非复制文件 |
-f |
强行复制文件或目录,不论目的文件或目录是否已经存在 |
-u |
只在源文件的修改时间较目的文件更新时,或是对应的目的文件并不存在,才复制文件 |
移动目录(mv)
1 | mv [option] <dir> <目标位置> |
| 参数 | 描述 |
|---|---|
-b |
若需覆盖文件,则覆盖前先行备份 |
-f |
如果目标文件已经存在,不会询问而直接覆盖 |
-i |
若目标文件已经存在时,就会询问是否覆盖 |
-u |
若目标文件已经存在,且源文件比较新,才会更新 |
-t |
该选项适用于移动多个源文件到一个目录的情况,此时目标目录在前,源文件在后 |
文件操作
查看文件信息(ll)
1 | ll <file> |

查看文件大小(du -h)
1 | du -h <dir/file> |
查看文件类型(file)
1 | file <file> |

查看文件(cat)
-
正序查看
1
cat [option] <file>
参数 描述 -A等价于 -vET-b对非空输出行编号 -e等价于 -vE-E在每行结束处显示 $ -n对输出的所有行编号,由 1 开始对所有输出的行数编号 -s有连续两行以上的空白行,就代换为一行的空白行 -t与 -vT等价-T将跳格字符显示为 ^I-u(被忽略) -v使用 ^和M-引用,除了 LFD 和 TAB 之外 -
倒序查看
1
tac <file>

文件计算行号查看(nl)
-
nl 命令在 linux 系统中用来计算文件中的行号。nl 可以将输出的文件内容自动加上行号,其默认的结果与 cat -n 有点不太一样。 nl 可以将行号做较多的显示设计,包括位数与是否自动补齐 0 等等的功能。
1
nl [option] [file]
参数 描述 -b指定行号指定的方式,主要有两种: -b a表示不论是否为空行,也同样列出行号(类似 cat -n)-b t如果有空行,空的那一行不要列出行号(默认值) -n列出行号表示的方法,主要有三种: -n ln行号在屏幕的最左方显示 -n rn行号在自己栏位的最右方显示,且不加 0 -n rz行号在自己栏位的最右方显示,且加 0 -w行号栏位的占用的位数

阅读文件
more
-
功能类似
cat,cat命令是将整个文件的内容从上到下显示在屏幕上。more命令会一页一页的显示,方便使用者逐页阅读,而最基本的指令就是按Enter向下滚动一行,按Space往下一页显示,按B键就会往回(back)一页显示,按=输出当前行行号,按下 H显示帮助,按下Q退出。1
more [option] <file>
参数 描述 +n从笫 n 行开始显示 -n定义屏幕大小为 n 行 +/pattern在每个档案显示前搜寻该字串(pattern),然后从该字串前两行之后开始显示 -c从顶部清屏,然后显示 -d提示“Press space to continue,’q’ to quiet”,禁用响铃功能 -p通过清除窗口而不是滚屏来对文件进行换页,与-c 选项相似 -s把连续的多个空行显示为一行 -u把文件内容中的下划线去掉
less
-
是 linux 正统查看文件内容的工具,功能极其强大
1
less [option] <file>
参数 描述 -e当文件显示结束后,自动离开 -f强迫打开特殊文件,例如外围设备代号、目录和二进制文件 -i忽略搜索时的大小写 -m显示类似 more 命令的百分比 -N显示每行的行号 -s显示连续空行为一行 -
常用操作:
符号 描述 /字符串 向下搜索“字符串”的功能 ?字符串 向上搜索“字符串”的功能 n 重复前一个搜索(与 / 或 ? 有关) N 反向重复前一个搜索(与 / 或 ? 有关) b 向前翻一页 d 向后翻半页 q 退出 less 命令 空格键 向后翻一页 向上键 向上翻动一行 向下键 向下翻动一行
head
-
用来显示档案的开头至标准输出中,默认 head 命令打印其相应文件的开头 10 行。
1
head [option] <file>
参数 描述 -q 隐藏文件名 -v 显示文件名 -c<字节> 显示字节数 -n<行数> 显示的行数

tail
-
用于显示指定文件末尾内容。常用查看日志文件,默认为尾部10行。
1
tail [option] <file>
参数 描述 -f循环读取 -q不显示处理信息 -v显示详细的处理信息 -c<字节>显示的字节数 -n<行数>显示行数
创建文件(touch)
1 | touch <file> |
-
批量创建文件
1
touch file{1..5}.txt

删除文件(rm)
1 | rm [option] <file> |

| 参数 | 描述 |
|---|---|
-f |
忽略不存在的文件,从不给出提示 |
-i |
进行交互式删除 |
-r |
指示 rm 将参数中列出的全部目录和子目录均递归地删除 |
-v |
详细显示进行的步骤 |
编辑文件(vim)
1 | vim <file> |
创建并写入文件(echo >>)
1 | echo "Text" >> <file> |

多行编辑(cat)
1 | cat >> <file> << eof |

复制文件(cp)
1 | cp [option] <file> <目标位置> |
| 参数 | 描述 |
|---|---|
-t |
指定目标目录 |
-i |
覆盖前询问(使前面的 -n 选项失效) |
-n |
不要覆盖已存在的文件(使前面的 -i 选项失效) |
-s |
对源文件建立符号链接,而非复制文件 |
-f |
强行复制文件或目录,不论目的文件或目录是否已经存在 |
-u |
只在源文件的修改时间较目的文件更新时,或是对应的目的文件并不存在,才复制文件 |
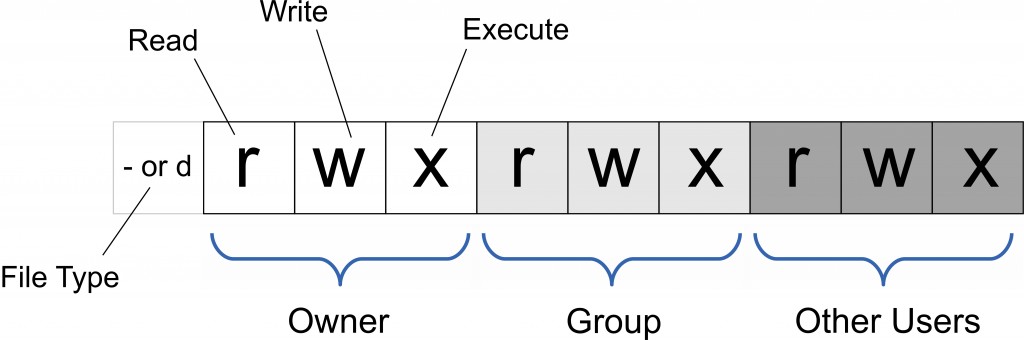
设置文件权限(chmod)
| # | 权限 | rwx | 二进制 |
|---|---|---|---|
| 7 | 读 + 写 + 执行 | rwx | 111 |
| 6 | 读 + 写 | rw- | 110 |
| 5 | 读 + 执行 | r-x | 101 |
| 4 | 只读 | r– | 100 |
| 3 | 写 + 执行 | -wx | 011 |
| 2 | 只写 | -w- | 010 |
| 1 | 只执行 | –x | 001 |
| 0 | 无 | — | 000 |
-
数字表示
1
chmod <rwx> <file>
-
文件调用权限分为三级 :
- 文件所有者(Owner)
- 用户所在用户组(Group)
- 其它用户(Other Users)
-
权限分为三种:
- 可读(Read)
- 可写(Write)
- 可执行(Execute)
-
-
字符表示
1
chmod <u><op><permission> <file>
-
用户组部分表示:
who 用户类型 说明 uuser 文件所有者 ggroup 文件所有者所在组 oothers 所有其他用户 aall 所有用户, 相当于 ugo -
符号部分表示:
Operator 说明 +为指定的用户类型增加权限 -去除指定用户类型的权限 =设置指定用户权限的设置,即将用户类型的所有权限重新设置 -
权限部分表示:
模式 名字 说明 r读 设置为可读权限 w写 设置为可写权限 x执行权限 设置为可执行权限 X特殊执行权限 只有当文件为目录文件,或者其他类型的用户有可执行权限时,才将文件权限设置可执行 ssetuid/gid 当文件被执行时,根据who参数指定的用户类型设置文件的setuid或者setgid权限 t粘贴位 设置粘贴位,只有超级用户可以设置该位,只有文件所有者u可以使用该位
-
-
效果相同语句举例:
1
2chmod a=rwx file
chmod 777 file1
2chmod ug=rwx,o=x file
chmod 771 file
移动文件(mv)
1 | mv [option] <file> <目标位置> |
| 参数 | 描述 |
|---|---|
-b |
若需覆盖文件,则覆盖前先行备份 |
-f |
如果目标文件已经存在,不会询问而直接覆盖 |
-i |
若目标文件已经存在时,就会询问是否覆盖 |
-u |
若目标文件已经存在,且源文件比较新,才会更新 |
-t |
该选项适用于移动多个源文件到一个目录的情况,此时目标目录在前,源文件在后 |
重命名文件(mv)
1 | mv <旧名称> <新名称> |
-
批量重命名:
1
2
3
4
5# 批量将这5个后缀为.txt的文本文件重命名为以.c为后缀的文件:
rename 's/\.txt/\.c/' *.txt
# 批量将这5个文件,文件名和后缀改为大写:
rename 'y/a-z/A-Z/' *.c
vim基础操作
进入vim编辑(普通模式)
1 | vim <file> |
-
游标操作:在普通模式下使用方向键或者h、j、k、l键移动游标
按键 说明 h 左 l 右(小写 L) j 下 k 上 w 移动到下一个单词 b 移动到上一个单词 -
快速操作:
命令 说明 x删除游标所在的字符 X删除游标所在前一个字符 Delete同 xdd删除整行 dw删除一个单词(不适用中文) d$或D删除至行尾 d^删除至行首 dG删除到文档结尾处 d1G删至文档首部
写入内容(插入模式)
-
进入:输入
i(insert/插入)或者a(append/追加) -
退出:按下Esc回到普通模式
-
更多命令:
命令 说明 i在当前光标处进行编辑 I在行首插入 A在行末插入 a在光标后插入编辑 o在当前行后插入一个新行 O在当前行前插入一个新行 cw替换从光标所在位置后到一个单词结尾的字符
命令模式
-
在普通模式下输入
:进入命令模式 -
退出vim:
命令 说明 :q!强制退出,不保存 :q退出 :wq!强制保存并退出 :w <文件路径>另存为 :saveas 文件路径另存为 :x保存并退出 :wq保存并退出 -
或者使用Shift + Z Z(按两次z)保存并退出vim
bash操作
定义变量
1 | declare tmp |
变量赋值
1 | tmp=shiyanlou |
读取变量
1 | echo $tmp |
新建子终端
1 | bash |
时间测量(time)
-
time 命令常用于测量一个命令的运行时间,包括实际使用时间(real time)、用户态使用时间(the process spent in user mode)、内核态使用时间(the process spent in kernel mode)。
1
time [command]
-
测量 date 命令运行的时间
1
time date
从上面的结果可以到:实际运行时间为 0.005s,用户 cpu 时间为 0.001s,系统 cpu 时间为 0.001s。
其中,用户 CPU 时间和系统 CPU 时间之和为 CPU 时间,即命令占用 CPU 执行的时间总和。实际时间要大于 CPU 时间,因为 Linux 是多任务操作系统,往往在执行一条命令时,系统还要处理其它任务。
搜索操作
where
-
只能检索二进制文件(
-b)、man帮助文件(-m)和源代码文件(-s)1
where find
which
-
在 PATH 变量指定的路径中搜索可执行文件的所在位置,一般用来确认系统中是否安装了指定的软件。
1
which <可执行文件名称>
whereis
-
通过
/var/lib/mlocate/mlocate.db数据库查找,主要用于定位可执行文件、源代码文件和帮助文件在文件系统中的位置。whereis 命令还具有搜索源代码、指定备用搜索路径和搜索不寻常项的功能。1
whereis [option] <file>
参数 描述 -b定位可执行文件 -m定位帮助文件 -s定位源代码文件 -u搜索默认路径下除可执行文件、源代码文件和帮助文件以外的其它文件 -B指定搜索可执行文件的路径 -M指定搜索帮助文件的路径 -S指定搜索源代码文件的路径
locate
-
locate 命令跟 whereis 命令类似,且它们使用的是相同的数据库。但 whereis 命令只能搜索可执行文件、联机帮助文件和源代码文件,如果要获得更全面的搜索结果,可以使用 locate 命令。
1
locate [option] <搜索字符串>
参数 描述 -q安静模式,不会显示任何错误讯息 -n至多显示 n 个输出 -r使用正则表达式做寻找的条件 -V显示版本信息 -
安装并立即更新一次数据库:
1
2
3sudo apt-get update
sudo apt-get install locate
sudo updatedb
find
-
主要作用是沿着文件层次结构向下遍历,匹配符合条件的文件,并执行相应的操作。
1
find [path] [option] [动作表达式]
默认路径是当前目录,默认表达式为 -print。
表达式 描述 -print将匹配的文件输出到标准输出 -exec对匹配的文件执行该参数所给出的 shell 命令 -name按照文件名查找文件 -type查找某一类型的文件 -prune不在当前指定的目录中查找,如果同时使用 -depth选项,那么-prune将被忽略-user按照文件属主来查找文件 -group按照文件所属的组来查找文件 -mtime -n +n按照文件的更改时间来查找文件, -n表示文件更改时间距现在小于 n 天,+n表示文件更改时间距现在大于 n 天1
2
3
4
5
6
7
8# 打印当前目录下的文件目录列表
find . -print
# 打印当前目录下所有以.txt 结尾的文件名
find . -name "*.txt" -print
# 打印当前目录下所有以.txt 或.pdf 结尾的文件名
find . \( -name "*.pdf" -or -name "*.txt" \)
# 打印当前目录下所有不以.txt 结尾的文件名
find . ! -name "*.txt"
打包与解压
zip
打包
-
将test目录打包
1
zip -r -q -o test.zip test
将目录 /home/shiyanlou/Desktop 打包成一个文件,
-r参数表示递归打包包含子目录的全部内容,-q参数表示安静模式,即不向屏幕输出信息,-o表示输出文件,需在其后紧跟打包输出文件名。 -
加密打包:
-e1
zip -r -e -q -o test.zip test
-
适配Windows换行:
-l,将LF转换为CR+LF1
zip -r -l -o test.zip test
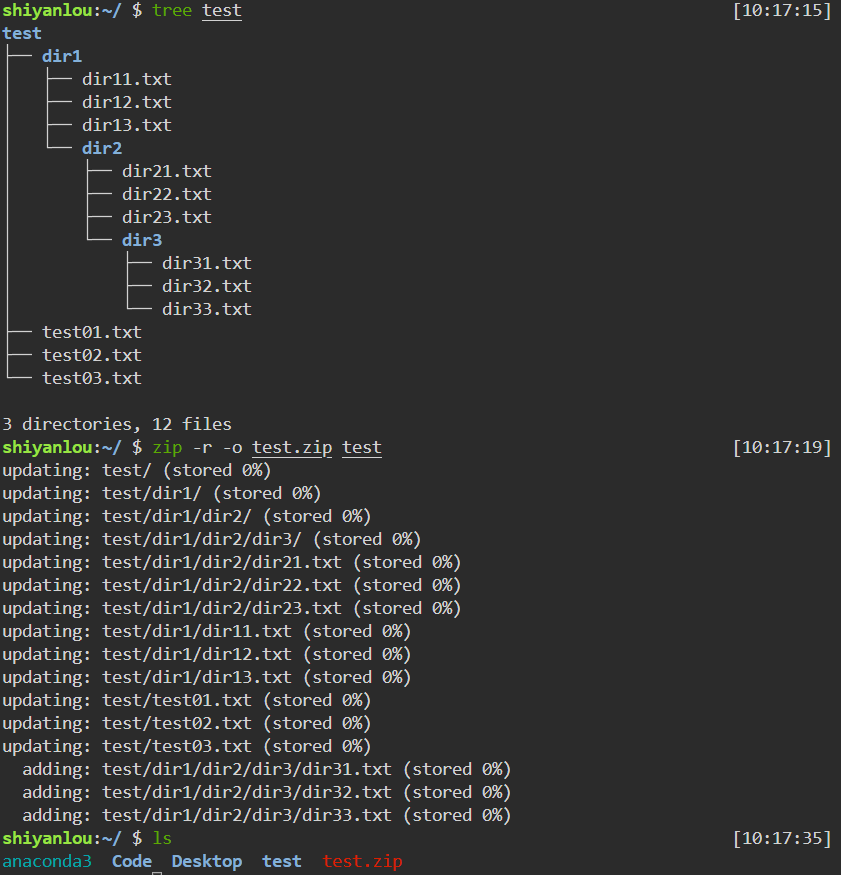

解压
1 | unzip <zip_file> |
-
安静模式:
-q,不存在的目录会自动创建1
unzip -q test.zip -d test
-
仅查看内容:
-l1
unzip -l test.zip
-
指定编码:
-O1
unzip -O GBK <中文压缩文件.zip>
tar
打包
-
打包为
.tar1
tar -Pcf test.tar test
-P保留绝对路径符,-c表示创建一个 tar 包文件,-f用于指定创建的文件名,注意文件名必须紧跟在-f参数之后 -
打包为
.tar.gz:-z1
tar -czf test.tar.gz test
-
更多格式:
压缩文件格式 参数 *.tar.gz-z*.tar.xz-J*tar.bz2-j


解压
-
解压
.tar1
tar -xf shiyanlou.tar [-C <tardir>]
解包一个文件(
-x参数)到指定路径的已存在目录(-C参数) -
解压
.tar.gz:-z1
tar -xzf shiyanlou.tar.gz


不解压查看
1 | tar -tf test.tar |
帮助操作
help
-
只能用于显示内建命令的帮助信息(仅能在bash中使用)
1
help ls
-
通常外部命令都有
--help参数1
ls --help
man
-
得到的内容比用 help 更多更详细,而且man没有内建与外部命令的区分
1
man ls
按下Q退出查看
info
-
安装:
1
2sudo apt-get update
sudo apt-get install info1
info ls
按下Q退出查看
语句控制
多语句执行
1 | 语句1; 语句2 ;语句3 |
条件执行(&& ||)
-
&&:如果前面的命令执行结果(不是表示终端输出的内容,而是表示命令执行状态的结果)返回0则执行后面的语句,否则不执行1
语句A && 语句B
-
||:和&&相反,返回1则执行后面的语句
管道(|)
-
将前一语句的输出作为下一语句的输入
1
ls -al /etc | less
文本处理
标准输出处理(xargs)
-
xargs 命令可以从标准输入接收输入,并把输入转换为一个特定的参数列表。
1
command | xargs [option] [command]
参数 描述 -n指定每行最大的参数数量 -d指定分隔符 -
将多行输入转换为单行输出
1
cat a.txt | xargs
-
将单行输入转换为多行输出
1
echo "1 2 3 4 5 6 7" | xargs -n 3
-
将单行输入转换为多行输出,指定分隔符为 i
1
cat b.txt | xargs -d i -n 3
-
查找当前目录下所有 c 代码文件,统计总行数
1
find . -type f -name "*.c" | xargs wc -l
文本切分(cut)
-
cut 命令是一个将文本按列进行切分的小工具,它可以指定分隔每列的定界符。
1
cut [option] <file>
参数 描述 -b以字节为单位进行分割 -c以字符为单位进行分割 -d自定义分隔符,默认为制表符 -f自定义字段 --complement抽取整个文本行,除了那些由 -c或-f选项指定的文本 -
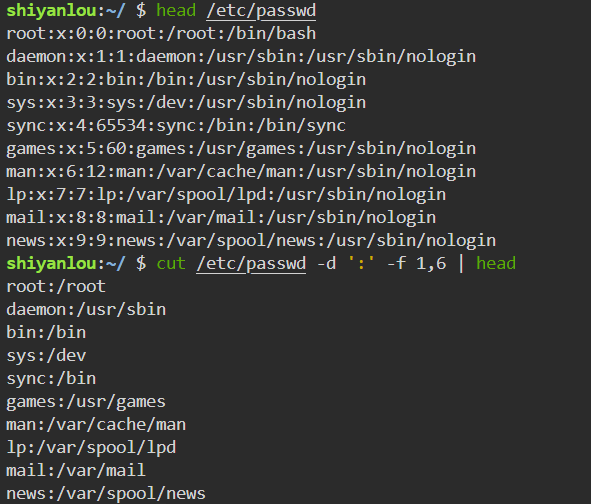
取出
/etc/passwd文件中以:为分隔符的第1个字段和第6个字段1
cut /etc/passwd -d ':' -f 1,6
-
取指定数量字符
1
2
3
4
5
6
7
8# 前五个(包含第五个)
cut /etc/passwd -c -5
# 前五个之后的(包含第五个)
cut /etc/passwd -c 5-
# 第五个
cut /etc/passwd -c 5
# 2到5之间的(包含第五个)
cut /etc/passwd -c 2-5
匹配字符串(grep)
-
grep 用来找到文件中的匹配文本,并且能够接受正则表达式和通配符,同时可以用多个 grep 命令选项来生成各种格式的输出。
-
grep 通过返回一个状态值来说明搜索的状态,如果模板搜索成功,则返回 0,如果搜索不成功,则返回 1,如果搜索的文件不存在,则返回 2
1
grep [option] <pattern> <file>
参数 描述 -c计算找到‘搜寻字符串’(即 pattern)的次数 -i忽略大小写的不同,所以大小写视为相同 -n输出行号 -v反向选择,打印不匹配的行 -r递归搜索 --color=auto将找到的关键词部分加上颜色显示 -
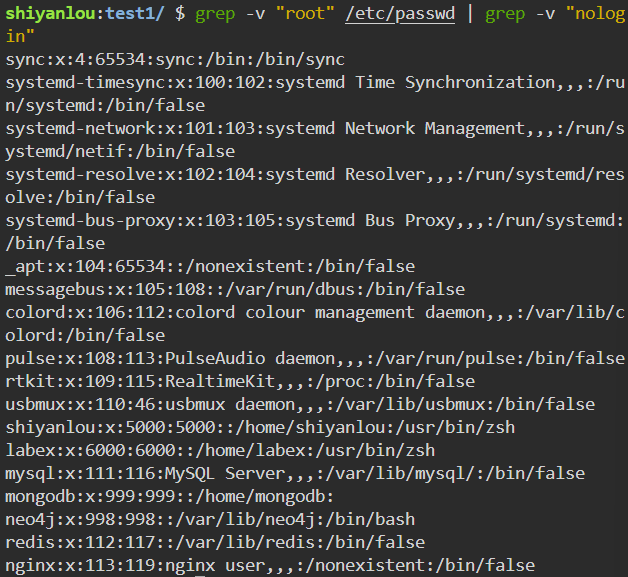
将
/etc/passwd文件中出现 root 的行取出来,关键词部分加上颜色显示1
2grep "root" /etc/passwd --color=auto
cat /etc/passwd | grep "root" --color=auto -
将
/etc/passwd文件中没有出现 root 和 nologin 的行取出来1
grep -v "root" /etc/passwd | grep -v "nologin"

内容统计(wc)
-
wc 命令是一个统计的工具,主要用来显示文件所包含的行、字和字节数。
1
wc [option] <file>
参数 描述 -c统计字节数 -l统计行数 -m统计字符数,这个标志不能与 -c标志一起使用-w统计字数,一个字被定义为由空白、跳格或换行字符分隔的字符串 -L打印最长行的长度 -
统计文件数
1
2# 统计/bin目录下的命令个数,即文件个数
ls /bin | wc -l
排序(sort)
1 | sort [option] <file> |
| 参数 | 描述 |
|---|---|
-n |
基于字符串的长度来排序,使用此选项允许根据数字值排序,而不是字母值 |
-k |
指定排序关键字 |
-b |
默认情况下,对整行进行排序,从每行的第一个字符开始。这个选项导致 sort 程序忽略每行开头的空格,从第一个非空白字符开始排序 |
-m |
只合并多个输入文件 |
-r |
按相反顺序排序,结果按照降序排列,而不是升序 |
-t |
自定义分隔符,默认为制表符 |
-
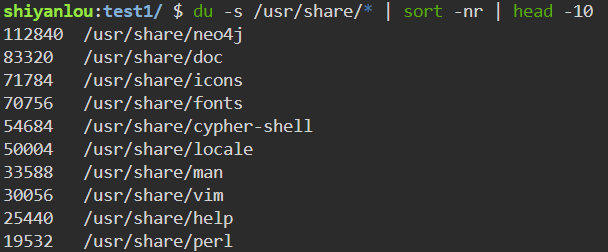
列出
/usr/share/目录下使用空间最多的前 10 个目录文件1
du -s /usr/share/* | sort -nr | head -10
-
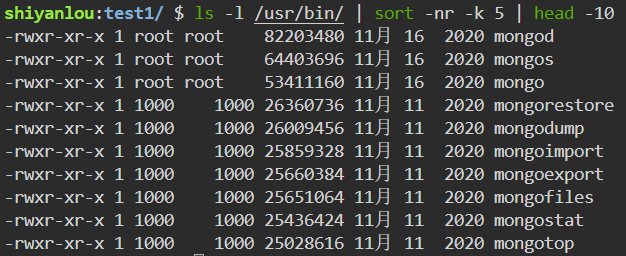
对 ls 命令输出信息中的空间使用大小字段进行排序
1
ls -l /usr/bin/ | sort -nr -k 5 | head -10
去重(uniq)
-
uniq 从标准输入或单个文件名参数接受数据有序列表,默认情况下,从数据列表中删除任何重复行。
-
uniq 只能用于排过序的数据输入,因此,uniq 要么使用管道,要么将排过序的文件作为输入,并总是以这种方式与 sort 命令结合起来使用。
1
uniq [option] <file>
参数 描述 -c在每行前加上表示相应行目出现次数的前缀编号 -d只输出重复的行 -u只显示唯一的行 -D显示所有重复的行 -f比较时跳过前 n 列 -i在比较的时候不区分大小写 -s比较时跳过前 n 个字符 -w对每行第 n 个字符以后的内容不作对照 -
找出
/bin目录和/usr/bin目录下所有相同的命令1
ls /bin /usr/bin | sort | uniq -d
-
现有文件内容如下,红色方框里的内容表示区号,现在要统计出各个区号的总人数
实现思路:首先按区号对每行信息排序,然后使用 uniq 命令对区号进行重复行统计。使用命令如下:
1
sort -k 4.1n,4.1n student.txt | uniq -c -f 3 -w 2
更改字符(tr)
-
tr 命令常被用来更改字符,我们可以把它看作是一种基于字符的查找和替换操作。换字是一种把字符从一个字母转换为另一个字母的过程,tr 可以从标准输入中替换、缩减和删除字符,并将结果写到标准输出。
1
tr [option] SET1 [SET2]
选项 说明 -d删除和set1匹配的字符,注意不是全词匹配也不是按字符顺序匹配 -s去除set1指定的在输入文本中连续并重复的字符 -
将输入的字符大写转换为小写
1
echo 'THIS IS SHIYANLOU!' | tr 'A-Z' 'a-z'
-
将输入的字符中的数字删除
1
echo 'THIS 123 IS S1HIY5ANLOU!' | tr -d '0-9'


Tab替换空格(col)
-
col命令可以将Tab换成对等数量的空格键,或反转这个操作1
col
选项 说明 -x将 Tab转换为空格-h将空格转换为 Tab(默认选项)1
2
3
4# 查看/etc/protocols中的不可见字符,可以看到很多^I,这其实就是Tab转义成可见字符的符号
cat -A /etc/protocols
# 使用 col -x将/etc/protocols中的Tab转换为空格,然后再使用cat查看,发现^I不见了
cat /etc/protocols | col -x | cat -A
合并字段(join)
-
join将两个文件中指定栏位相同的行连接起来,即按照两个文件中共同拥有的某一列,将对应的行拼接成一行
1
join [option] <file1> <file2>
选项 说明 -t指定分隔符,默认为Tab -i忽略大小写的差异 -1(数字1)指明第一个文件要用哪个字段来对比,默认对比第一个字段 -2指明第二个文件要用哪个字段来对比,默认对比第一个字段 -
将两个文件中的第一个字段作为匹配字段,连接两个文件
1
join a.txt b.txt
-
指定两个文件的第三个字段为匹配字段,连接两个文件
1
join -1 3 -2 3 c.txt d.txt

简单合并文件(paste)
-
paste 命令的功能正好与 cut 相反。它会添加一个或多个文本列到文件中,而不是从文件中抽取文本列。它通过读取多个文件,然后把每个文件中的字段整合成单个文本流,输入到标准输出。
1
paste [option] <file>...
参数 描述 -s将每个文件合并成行而不是按行粘贴 -d自定义分隔符,默认为制表符 -
将
student.txt和telphone.txt文件中的内容按列拼接1
paste student.txt telphone.txt
-
将
student.txt和telphone.txt文件中的内容按列拼接,指定分隔符为:1
paste student.txt telphone.txt -d ':'
-
将
student.txt和telphone.txt文件中的内容各自拼接成一行1
paste -s student.txt telphone.txt
比较文本文件(comm)
-
comm 命令将逐行比较已经排序的两个文件。显示结果包括 3 列:第 1 列为只在第一个文件中找到的行,第 2 列为只在第二个文件中找到的行,第 3 列为两个文件的共有行。
1
comm [option] <file1> <file2>
参数 描述 -1(数字1)不输出文件 1 特有的行 -2不输出文件 2 特有的行 -3不输出两个文件共有的行 -
比较
file1.txt和file2.txt两个文件的内容1
comm file1.txt file2.txt
-
比较
file1.txt和file2.txt两个文件的内容,只显示两个文件共有的内容1
comm -12 file1.txt file2.txt
监测文件差异(diff)
-
类似 comm 命令,diff 命令被用来监测文件之间的差异。然而,diff 是一款更加复杂的工具,它支持许多输出格式,并且一次能处理许多文本文件。diff 能够递归地检查源码目录,通常称之为源码树。diff 程序的一个常见用例是创建 diff 文件或者补丁,它会被其它程序使用,例如 patch 程序,来把文件从一个版本转换为另一个版本。
1
diff [option] <file>
参数 描述 -c上下文模式,显示全部内文,并标出不同之处 -u统一模式,以合并的方式来显示文件内容的不同 -a只会逐行比较文本文件 -N在比较目录时,若文件 A 仅出现在某个目录中,预设会显示:Only in 目录。若使用 -N 参数,则 diff 会将文件 A 与一个空白的文件比较 -r递归比较目录下的文件 -
显示
file1.txt和file2.txt两个文件的差异1
diff file1.txt file2.txt
上面结果显示中的“1d0”表示
file1.txt文件比file2.txt文件多了第一行,“4c3,4”表示file1.txt文件的第四行和file2.txt文件的第三、四行不同。diff 的 normal 显示格式有三种提示:
- a - add
- c - change
- d - delete
-
从上面例一的显示结果可以知道,
file1.txt和file2.txt两个文件的差异不易直观看出,这时可以使用上下文模式显示1
diff -c file1.txt file2.txt
+添加行,这一行将会出现在第二个文件内,而不是第一个文件内-删除行,这一行将会出现在第一个文件中,而不是第二个文件内!更改行,将会显示某个文本行的两个版本,每个版本会出现在更改组的各自部分 -
查看
file1.txt和file2.txt两个文件的差异,使用统一模式显示1
diff -u file1.txt file2.txt
文本中应用更改(patch)
-
patch 命令被用来把更改应用到文本文件中。它接受从 diff 程序的输出,并且通常被用来把较老的文件版本转变为较新的文件版本
1
patch [option] <file>
参数 描述 -p num忽略几层文件夹 -E如果发现了空文件,那么就删除它 -R取消打过的补丁 -
生成
file1.txt和file2.txt的 diff 文件,然后应用 patch 命令更新file1.txt文件1
2diff -Naur file1.txt file2.txt > patchdiff.txt
patch < patchdiff.txt -
取消上面打过的补丁
1
patch -R < patchdiff.txt
空间管理
查看目录结构(tree)
1 | tree <dir> |
安装方式:
1 | sudo apt-get update |
磁盘占用情况(df)
-
df (disk free)命令的功能是用来检查 linux 服务器的文件系统的磁盘空间占用情况。可以利用该命令来获取硬盘被占用了多少空间,目前还剩下多少空间等信息。
1
df [option] <file>
参数 描述 -a全部文件系统列表 -h方便阅读方式显示 -i显示 inode 信息 -T文件系统类型 -t<文件系统类型>只显示选定文件系统的磁盘信息 -x<文件系统类型>不显示选定文件系统的磁盘信息 -
显示磁盘使用情况
1
df
-
以 inode 模式来显示磁盘使用情况
1
df -i
-
列出文件系统的类型
1
df -T
-
显示指定类型磁盘
1
df -t ext4
查看使用空间(du)
-
du(disk usage)命令也是查看使用空间的,但是与 df 命令不同的是 Linux du 命令是对文件和目录磁盘使用的空间的查看。
1
du [option] <file>
参数 描述 -a显示目录中所有文件的大小。 -b显示目录或文件大小时,以 byte 为单位。 -c除了显示个别目录或文件的大小外,同时也显示所有目录或文件的总和。 -k以 KB(1024bytes)为单位输出。 -m以 MB 为单位输出。 -s仅显示总计,只列出最后加总的值。 -h以 K,M,G 为单位,提高信息的可读性。 -
显示指定文件所占空间,以方便阅读的格式显示
1
du -h file1.txt
-
显示指定目录所占空间,以方便阅读的格式显示
1
du -h Desktop
-
显示几个文件或目录各自占用磁盘空间的大小,并且统计总和
1
du -ch file1.txt file2.txt
-
按照空间大小逆序排序显示
1
du -h | sort -nr | head -10



